
Much like coding, validation of ML/AI Models requires handling complexity… and a little bit of magic.
As I was presenting a webinar last month based around the complexities and common issues of risk modeling, a question came up surrounding the validation of models utilizing artificial intelligence and machine learning algorithms. In particular, the question regarded what sort of practical approaches we can take, and how those of us outside of the AI experts can understand a technical topic like this one. Or, at the very least, how we can (as non-experts) comprehend the gist of what’s required, and leave the more in-the-weeds aspects to those machine masters.
To accomplish this paradigm shift in understanding financial models, let’s first start by talking about the methods and considerations in general risk model validation. From there, we’ll take those cornerstones of the field and expand them into the space of AI/ML as best we can.
The Keys to Overall Model Validation
Financial model validation is sometimes thought of as an artform with lots of guidance from regulators and accountants. In particular (in the US, at least), as articulated in April 4, 2011’s OCC 2011-12: Supervisory Guidance on Model Risk Management – Section 5, lays out a set of guidelines to guide you on your path toward model validation. The three major tenets of model validation (in this regulation, at least) are:
- Evaluation of conceptual soundness
- Ongoing monitoring, including process verification and benchmarking, and
- Outcomes analysis.
(SMARTER risk management has broken this into Purpose, Assumptions, Input, Transformation, Output, Results and reporting, as those whose models we have validated can attest to.)
Number 1 and 3 includes guidance toward input and reporting, which we won’t discuss here due to the fact they’ll be handled similarly to non-AI/ML models. What’s key in validating AI/ML models, then, is the ongoing monitoring. The document itself says that “process verification checks that all model components are functioning as designed,” and that benchmarking “is the comparison of a given model’s inputs and outputs to estimates from alternative internal or external data and models.” These are all really good descriptions that together make sense, but what they mean in the scope of AI/ML is a little different. For process verification, it’s more of a question of ensuring that the process is updating appropriately and understandably (for purposes of explainability). For benchmarking, it’s a question of whether constantly updating algorithms will have a feasible runtime in the long term. But those are gross oversimplifications: what do we actually need for validation? The answer is expertise.
An Exercise in Expertise
The expertise that we need to validate these models is far reaching. Unless you’ve found a single person who understands AI, financial risk models, statistics, and data science (which is one hefty wish list), you’re going to need several people along the way who understand the different aspects. Along with that, they must have an intimate enough familiarity with the inputs and outputs of each step to understand when something looks good and when it looks, well, wrong.
For example, Towards Data Science has an article that emphasizes the complexity of thorough validation in machine learning for both comprehension and benchmarking. There’s a list of about 10 different validation methods that are useful for different use cases that are explained there. This emphasizes that most ML model validators use a process called k-Fold Cross Validation, which utilizes a small data sample to estimate the “skill” of the model. The process is complex in itself—here’s a guide going over the basics—but it’s a small subset of the options available for ML validators.
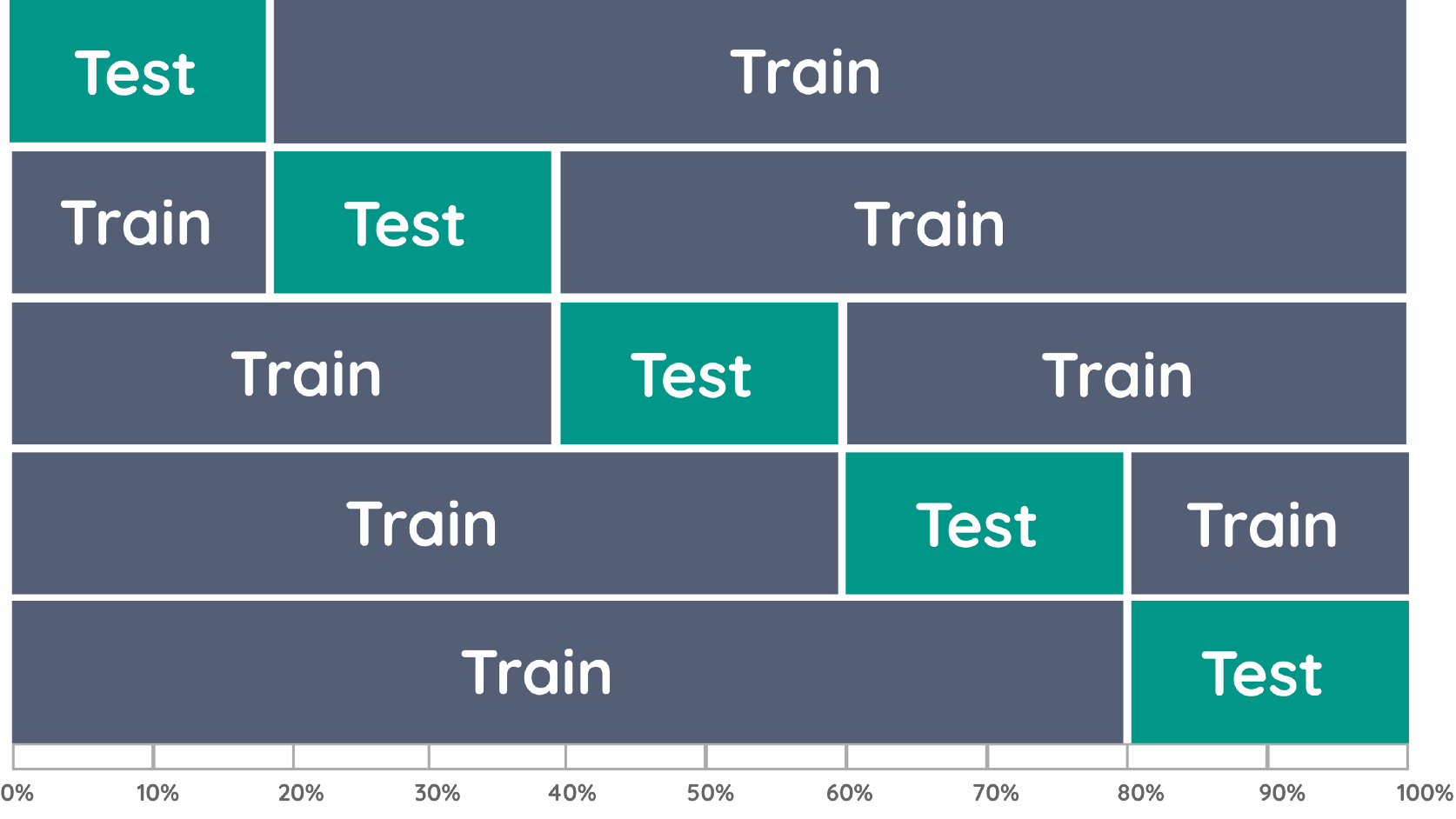
A visualization of k=5-fold cross validation, delineating between test data and training data
If you’re newly transitioning into an ML model from a more traditional mathematic model, another helpful validation test is to compare the results of your new model to the results of your old. This method is tried and true—you’ve probably used something similar before in your career, if you’re a data scientist—but that doesn’t mean it’s not worth going over once more. The Towards Data Science article recommends an approach called the Wilcoxon, McNemar’s, and 5x2CV paired tests for this purpose. The convenient thing? The article also features methods of actually running these procedures, for those who are less ML/computer science robust.
This is by no means an exhaustive list of the options for ML/AI validators, and it doesn’t intend to be. What I’ll leave you with is a rule of thumb: the more complex your ML/AI algorithm, the more robust your associated validation processes need to be. And the more techniques that will need to be evaluated.
The State of the Machine
Model validation is going to be one of the most integral and evolving processes in the space of ML/AI algorithms over the next few years. As the technology becomes more mature and usage becomes even more prevalent, it’s likely the tools with which we validate the models will themselves follow suit. One key we haven’t even mentioned yet is that many ML/AI models do automatically redevelop on a regular and shifting schedule. It’s likely that each step that it progresses toward a “complete” model will require additional validation AND approval until you can be certain any adjustment it makes still gives desired results. Change results in a need to validate the change.
A famous Warren Buffett quote is “Risk comes from not knowing what you’re doing.” It’s easy to see how this can be represented in ML risk modeling. After all, the point of ML models is that they adapt and become the best versions of themselves to give you the most accurate results. Without a dedicated expert validator involved, though, the model risk involved with AI/ML skyrockets. Only through advanced and consistent benchmarking and verification can we be sure that these models continue to get better and stay accurate. If we don’t monitor the algorithms and the risk models, we put ourselves in danger of an AI uprising, or worse: an inaccurate and biased model.
As I stated at the beginning, AI/ML model validation requires a paradigm shift in how models are viewed. The firm or person who built the model may not always help you understand how to look at or validate the model in a way that is understandable. When I was in college I had a roommate who was working on his PhD in Physics/Materials Science. We would be out and about and someone would ask him what he was studying. He loved to launch into a long explanation which was guaranteed to kill the mood at any social event. This same effect can take place when you ask someone, “How does the AI/ML model work and produce results?” The “black box” model that was vilified during the 2000’s may reappear with an AI/ML model. SMARTER risk management, LLC is here to help. Let’s talk…
0 Comments